Hello community,
this is a follow up to the “Inexplainable race condition in SDL Renderer” discussion. I have now restructured my application (which did not fix the issue, but improved portability) and ran into efficiency issues.
This is what my application needs to do:
Render contents of 4 buffers with pixel data to 4 windows. Buffers are provided by a secondary thread while rendering is done on the main thread. Keyboard and mouse events are processed in the main thread. In more detail:
- Main thread: Get and process events at a frequency of about 200 Hz. At the same frequency check if rendering is required and if true, render contents of buffers with pixel data to 1, 2, 3 or all of the windows.
- Secondary thread: Run the primary task of my application and tell the main thread when data is available for rendering. Therefore the mentioned buffers are filled with pixel data (thread-safe) and an atomic variable is set to 1 to signal the main thread that rendering is requested. The data is provided at an average frequency of 68 Hz. Variability through the 200 Hz frequency of the main thread is not an issue.
Code simplified for single window:
Shared variables:
static Uint8 buffer[4*1024*1024];
static SDL_SpinLock bufferLock;
static SDL_atomic_t bufferUpdated;
Main thread:
Uint32 r, g, b, a, d, format;
SDL_Event event;
SDL_Window* sdlWindow = SDL_CreateWindow(PROG_NAME, SDL_WINDOWPOS_UNDEFINED, SDL_WINDOWPOS_UNDEFINED, 1120, 832, 0);
SDL_Renderer* sdlRenderer = SDL_CreateRenderer(sdlWindow, -1, SDL_RENDERER_ACCELERATED);
SDL_Texture* sdlTexture = SDL_CreateTexture(sdlRenderer, SDL_PIXELFORMAT_UNKNOWN, SDL_TEXTUREACCESS_STREAMING, 1120, 832);
SDL_RenderSetLogicalSize(sdlRenderer, 1120, 832);
SDL_QueryTexture(sdlTexture, &format, &d, &d, &d);
SDL_PixelFormatEnumToMasks(format, &d, &r, &g, &b, &a);
SDL_Surface* sdlSurface = SDL_CreateRGBSurface(SDL_SWSURFACE, 1120, 832, 32, r, g, b, a);
while (1) {
SDL_PollEvent(&event);
// some event handler function
SDL_Delay(5)
if (SDL_AtomicSet(&bufferUpdated, 0) {
SDL_AtomicLock(&bufferLock);
SDL_UpdateTexture(sdlTexture, NULL, buffer, sdlSurface->pitch);
SDL_AtomicUnlock(&bufferLock);
SDL_RenderClear(sdlRenderer);
SDL_RenderCopy(sdlRenderer, sdlTexture, NULL, NULL);
SDL_RenderPresent(sdlRenderer);
}
}
Secondary thread:
void bufferCopy(Uint8* src) {
SDL_AtomicLock(&bufferLock);
memcpy(buffer, src, sizeof(buffer);
SDL_AtomicSet(&bufferUpdated, 1);
SDL_AtomicUnlock(&bufferLock);
}
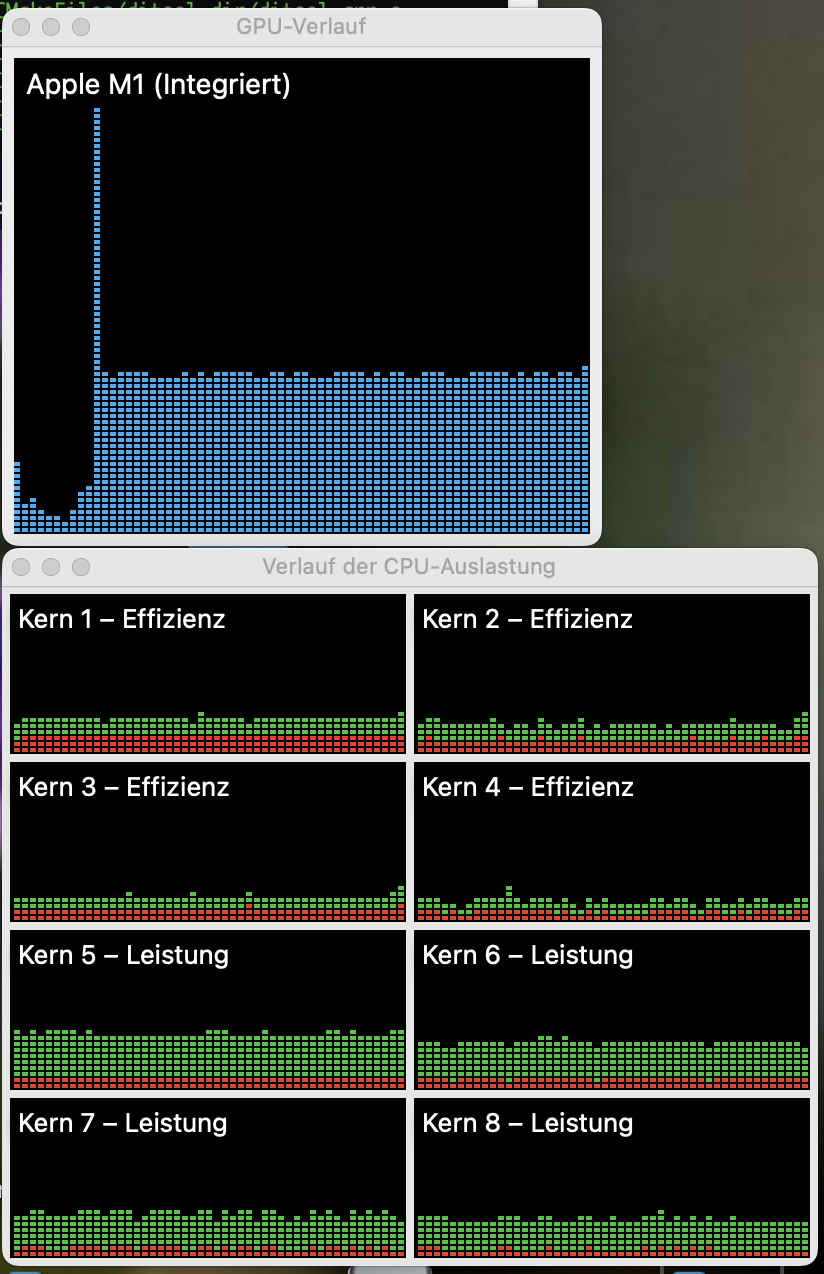
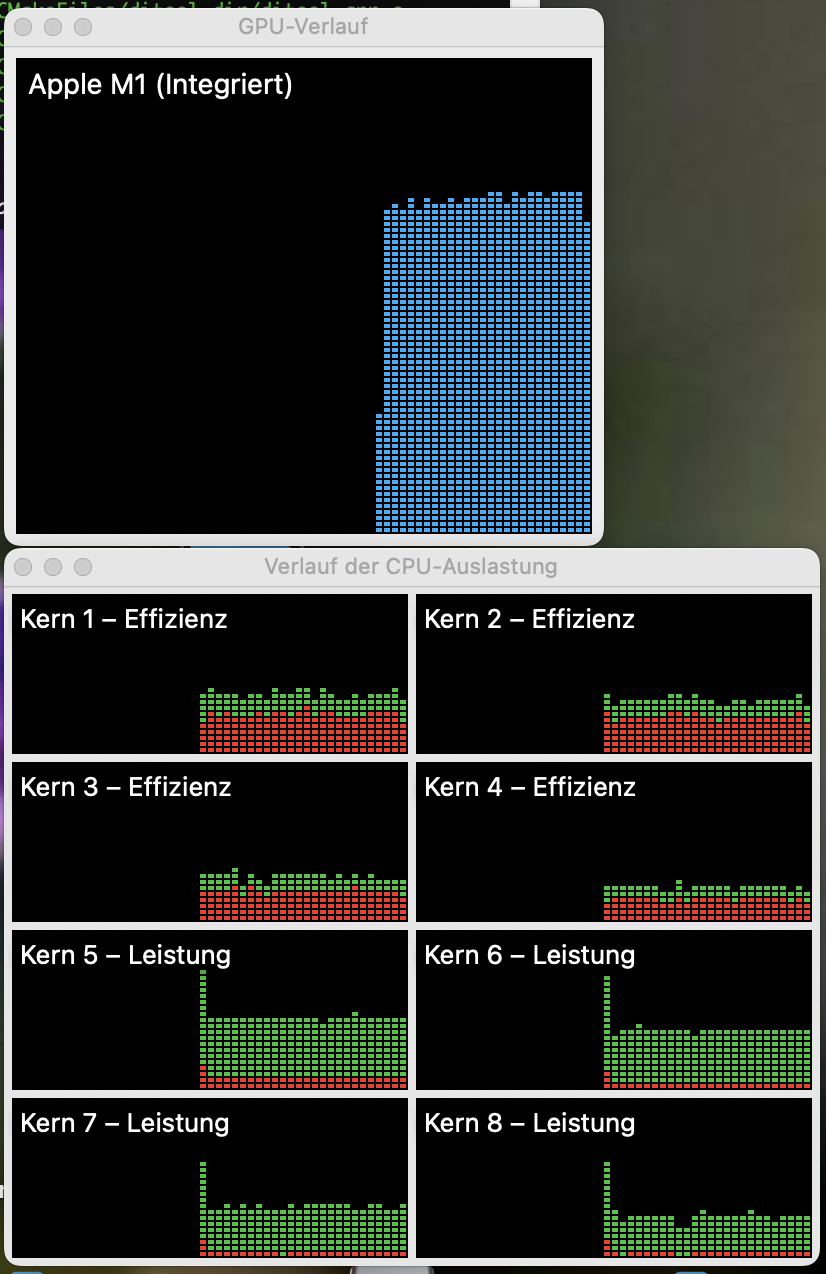
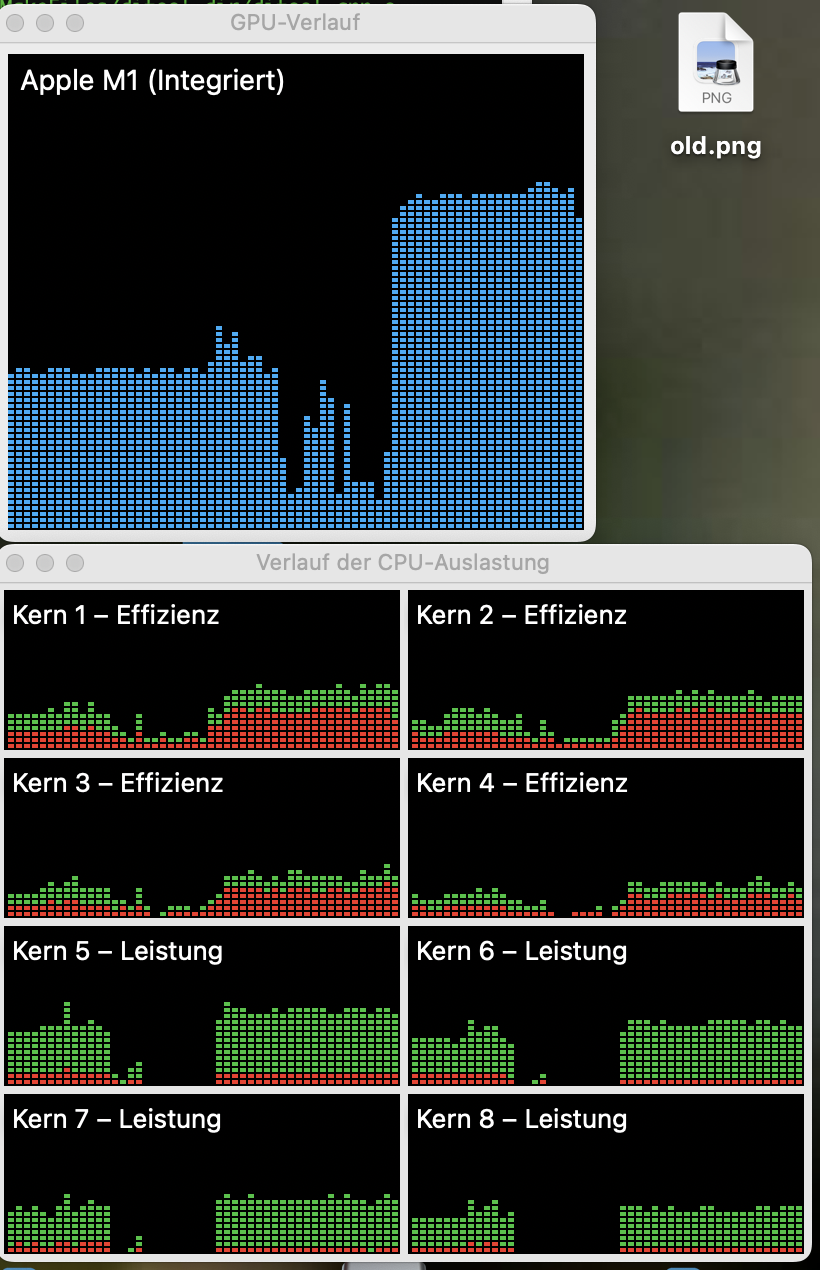
I now have the problem, that my current implementation is very inefficient. It uses way too much CPU- and GPU power. The original implementation involved rendering in four secondary threads at VSYNC while the main thread provided the data. That was way more efficient but not portable.
Any ideas how to efficiently implement this are welcome!
btw. Using SDL_LockTexture()/SDL_UnlockTexture() instead of SDL_UpdateTexture() has no noticable effect.